自作DBを始めたい人におすすめの本
この記事は、慶應理工アドベントカレンダー2021の20日目の記事です。
カレンダー全日埋まってすごい 🎉🎉
「Database Design and Implementation」という簡素なDBをスクラッチで作っていく本に取り組んだので、その読了エントリです。
 (English Edition)")
こんな人におすすめ
MySQLやPostgreSQLを使った経験はあるが、DBの理論やその実装はあまり詳しくない人に特におすすめです。特に自作〇〇*1に興味がある人は間違いなく楽しめると思います。単純に本に紹介されている理論と実装に取り組むだけでもいいですのですが、豊富な拡張課題が用意されているので是非取り組むといいと思います。理論だけ紹介されて実装は全部自分で設計からやらないといけないので時間かかりますが... この本は英語で書かれていますが、わかりやすい説明だったので特に苦労しませんでした。
最終的にこんなクエリが実行できるようになります。
自作DB、こんなクエリが実行できるようになったぜー pic.twitter.com/q0tqyV8a4V
— サラダチキン (@salachike) 2021年8月26日
その他にもORDER BYとかGROUP BYとかデータを集約するクエリの実行や、インデックスを張ったりもできます!結構すごくないですか?
内容について
備忘録を兼ねてどんな内容を扱うのかまとめてみます。読んでてあんまり面白くないと思いますが、興味持ってくれると嬉しいです。 本のサンプルコードはJavaですが好きな言語で実装して大丈夫です。 ちなみに自分はC++で取り組みました。
Chap1--2: Introduction
データベースとは何なのかの説明。 モチベーションが否応なく?高まる...
Chap3: Disk and File Management
ディスクドライブの物理的な構成、アクセス高速化のための工夫 (Disk caches, Cylinders, and Disk Striping)、SSDなどについて説明と、ブロック単位のメモリ領域としてページという概念の説明があります。ディスク上にファイル単位でデータ全体を保存し、ブロック単位でデータの読み書きをおこなうFile Managerを実装します。
Chap4: Memory Management
ディスクアクセスはメモリアクセスに比べてめちゃくちゃ遅いので、In-Memoryでデータを管理して、必要に応じてディスクに書き込むようなDBの設計にしたい。そのためにDBのログをファイルに書き込むLog Managerと、ページの集合体であるBuffer Poolの管理をおこなうBuffer Managerを実装します。 Buffer Poolが全部使用されているときに、どのBufferをディスクに書き込んでから割り当て可能にするかを決定するアルゴリズムもいくつか紹介されます。好きなアルゴリズムを実装すると面白いと思います。
Chap5: Transaction Management
TransactionやACIDとかが題材ですが、理論も私には難しく何度も同じ箇所を読み返しました。Transactionのロールバックや、ログファイルを元にDBを整合性のある状態するRecovery Managerを実装します。また並行で動いている複数のTransactionにも対応できるように、共有・排他ロックをおこなうConcurrency Managerを実装します。
Chap6: Record Management
ファイルにレコードを保存するRecord Managerを実装します。レコードの先頭位置から、それぞれのフィールドのオフセット分を足した箇所に値を読み書きするようにします。
Chap7: Metadata Management
テーブルのレコードの構造(フィールドの長さと型 ( CHAR(8)とか )、オフセット)や、インデックスが張られたフィールド名などのメタデータを管理するMetadata Managerを実装します。
Chap8: Query Processing
select、project、productといった演算は関係代数的にはどういうことなのかが説明されてます。Iterativeにレコードを走査できるような処理を書きます。
Chap9: Parsing
クエリをパースする再帰下降パーサーを書きます。Nand2Tetrisのコンパイラの章で再帰下降パーサーを書いた経験が活きました...

Chap10: Planning
クエリをパースした結果から、実行計画を作るPlannerを実装します。パース結果のみだと実行計画は複数考えられる場合があるので、メタデータからブロックアクセス数などのコストを見積もりして、コストが低い実行計画を選ぶようにします。
Chap11: Interface
今までの機能をアプリケーションとして使えるようにします。
Chap12: Indexing
インデックスとしてB-Treeインデックスを実装します。インデックスを張ったフィールドがユニークな値が多い場合、ディスクアクセス数が少なくなりクエリの高速化が期待できます。 B-Treeの実装は難しかったので、もう一回復習したいところ。

Chap13: Materialization and Sorting
仮テーブルへの書き込み処理を実装します。 パイプライン化されたクエリの場合、中間の出力を一度仮のテーブルに書き込んだ方がブロックアクセス数がトータルで少なくなる場合があります。
以下のクエリを見てみましょう。
SELECT * FROM T1, T2 WHERE T1.FIELD= HOGE AND T2.FIELD = HUGA AND T1.ID = T2.ID;
ナイーブな実行計画だと、2つのテーブルT1とT2のレコードを2重ループで全探索していきます。これはレコード数の多いテーブルの場合非常に時間がかかります。ここで仮テーブルの出番です。テーブルT1で T1.FIELD = HOGE のレコードとテーブルT2で T2.FIELD = HUGA のレコードをそれぞれ別の仮テーブルに書き込みます。最後に2つの仮テーブルを全探索してT1.ID=T2.IDのレコードを出力します。このレコードを絞る方法の方がナイーブな実行計画よりブロックアクセス数が少なくなる可能性が高いです*2*3。
Chap14: Effective Buffer Utilization
複数のバッファーを使ってブロックアクセス数が少なくなるように、ORDER BYで使っていたマージソートを改造します。
Chap15: Query Optimization
複数の実行計画が考えられるクエリについてディスクアクセスがなるべく少なくなるようなヒューリスティックな実行計画の選択アルゴリズムの紹介とその実装をおこないます。
まとめ
DBというと凄腕エンジニアたちが叡智を結集して作っているようなイメージを持っていましたが、ひとつずつ理論と実装の対応を追っていけば普通の人間でも理解できることが分かって嬉しかったです。
今は「Operating System Concepts」というOSの有名な教科書を読んでいるので、それも読み終えたら書評を書きたいです。
*1:DB、OS、CPU、言語、コンテナ、TCP/IP プロトコルスタックetc
*2:T1.FILED = HOGEやT2.FIELD = HUGAでレコード数が絞られない場合、効果薄いです。
*3:例えばテーブルT1とT2で10000レコードずつあって、T1.FILED=HOGEとT2.FILED=HUGAのものが100個ずつあると仮定します。単純にコスト比較するとナイーブな実行計画は全探索で10000 * 10000 = 100000000、仮テーブルを使う場合 10000 (T1でT1.FIELD = HOGEのものを探す) + 10000 (T2でT2.FIELD = HUGAのものを探す) + 100*100 (仮テーブルの全探索) = 30000とかです。もちろん仮テーブルへの書き込みというオーバヘッドもあります。
Web系企業エンジニア就活体験記
この記事は、慶應理工アドベントカレンダー2021の4日目の記事です。
後輩の@yapatta_progが企画してくれました。ありがとう!
はじめに
Twitterなどのソーシャルメディアには、技術的に突出した学生がたくさん生息してるように思えます。彼ら/彼女らの活躍のツイート*1を見ると、「すごい!」という純粋な賞賛の気持ちと同時に、「自分はしょぼすぎ...」と自己肯定感が下がってしまうことが私は時折あります。しかしそのような学生は世間的にはごく僅かで、決して多数ではありません。普通の院生である私もWeb系企業でエンジニア*2になりたいと決めてはいたものの、就活開始時は化け物のような学生と競争しないといけないのかと思うと非常に不安でした。ですが内定はもらえたので、就活で感じた最低限やっておいた方が良いことなどについて書きます。誰かの役に立つと嬉しいです。再現性がなく主観的な記事なのはご了承ください。
自己紹介
大学はバレてるので省きますが22卒のM2です。ヒューマンコンピューターインタラクション分野の研究をしていてます。 Web系の企業の中でもメガベンチャーと呼ばれる大きめの企業を中心に受け、力試しで外資系テック企業のソフトウェアエンジニア職も受けたりしました。 M1の前半は研究を頑張っていたので*3、夏のインターンには行きませんでした。M1の12月から選考を受け始め、翌年の2月に就活を終了しました。 最終的な結果は2社からオファー、3社落ち、2社途中辞退という感じです。
就活時には研究成果だけ少しあって *4、競プロは苦手でまともなチーム開発経験*5も十分にはありませんでした。ちなみにB4の夏は、有名なWeb系企業のインターンに参加したくて選考をたくさん受けましたがほとんど落ちました。
何をするべきか
研究
研究室に所属しているor予定の学生は研究をコツコツ進め、結果を出すことをオススメします。普通に武器になります*6*7。結果を出すというのは名の知れたトップ国際会議やジャーナルに論文を通すということだけではないと思っていて、「どうしてその研究をしていて、先行研究にはどのような問題があり、それに対してどのようなアプローチを取り、どのような結果が出たか」という研究のストーリーをしっかり語れるレベルまでになるということです。実際私はほとんどの企業の面接で研究の話をしましたが、どこの会議に通っているとかは全く見られていないと感じました*8。むしろ研究を進める上での論理的思考やエンジニアリングの観点でどのような工夫をしたのかも考えておくと、エンジニアとの面接では良いと思います*9。あと口頭で難しい研究内容を言われても聞き手は辛いと思うので、イラストを多く入れたスライドを用意し、分野に詳しくない人でも理解できるような説明を心がけるといいと思います。
個人開発
Web系企業でエンジニアとして働きたい以上、個人開発で作った製作物が皆無なのはまずいと思います。手を動かして何か作れる力がある、モチベーションがあるということをアピールしましょう。一人で作るのはちょっという人は知り合いを巻き込んで、チーム開発するのもいいと思います。ハッカソンに出るのも手っ取り早いですね。私は強化学習アルゴリズムを使って学習したエージェントと対戦するマルバツゲームを個人開発しました*10。フロントエンドはReact、バックエンドはPythonで開発し、CircleCIを使ってテストやデプロイの自動化をしてという話を面接ではしていました。ものすごいクオリティの高いアプリケーションなどを作らないといけないとは思いません。アプリケーションを自分で完成して公開されていることが重要だと思います。
コーディングテスト対策
私が受けた限り、国内のWeb系企業のコーディングテストはそこまで難しいと思いませんでした*11。おそらく足切り程度にしか使われていないのだと推測します。 とはいえ通過できなかったたらそこで選考終了なので、最低限は対策した方が良いです。ハッシュテーブルやスタック、キューとか基本的なデータ構造とかに習熟して、全探索で無理矢理解くということをしなければ大丈夫だと思います。ただ力試しで受けた外資系テック企業のソフトウェアエンジニア職のコーディングテストはずっと難しく通過できませんでした。LeetCodeなどをやりこまないといけないのだと感じました。
なぜエンジニアとして働きたいかを考える
企業の人はなぜエンジニアとして働きたいのか、どのようなエンジニアなりたいのかを知りたがっていると思います。この点を選考で考慮してくれる企業の新卒採用は、武器がなくて不安な人に取って幸運です。最大限活用するべきです*12。「アプリケーションを作るのが好き」とかだけだと抽象的すぎるので、「どうやって実現するのかを考えるのが好き」とか「こういう価値をユーザーに届けたい」、「この技術を突き詰めたい」とかより具体的な理由を考えて、自分の経験と照らし合わせて話せると良いと思います。また「入社した後にどのような仕事をしたいのか」も十中八九聞かれる質問なので準備しておきましょう。特にその企業でしかできないことだと◎だと思います。
その他
インターンに行けなくても大丈夫
1dayとかの説明会レベルのものではなく、2週間から数ヶ月就業するインターン(有給)はエンジニアとしてのスキル向上だけではなく、キャリアについて考えるきっかけになると思います。 私はB4の夏に参加したエンジニアインターンではあまり成果は出せませんでしたが、ものすごく仕事が楽しくてWeb業界を目指すようになりました。 ただ有名な企業のエンジニアインターンは一部の優秀な上澄み学生が独占しているように思えるので、参加するのは厳しくなっているのかもしれません。 私はM1ではインターンに行かずに本選考だけ受けましたが、アピールできるポイントがあるのならインターンに参加できなくても全く問題ないと思います*13。「みんなインターンに行ってるから自分もいかないとやばい」みたいな同調圧力もあるのかもしれませんが、何をすれば自分に一番プラスになるのかを考えるのをオススメします。
入りたい企業だけまず受ける
本当に自分が入社しても良い企業だけ最初は選考を進めた方が良いと思います。Web業界は選考がほとんど通年に渡りおこなわれているので、最悪全落ちして手駒がなくなってしまった後に次の候補を探しても遅くはないと思います。週のうちに何社も面接が入っているくるようになると精神的に疲労してくるので、あんまり入社する気はないけど保険のために受けておくという考えは個人的にはオススメしません。もし内定まで出て辞退するのは、気まずいですよね。
面接で話すエピソードとかをNotionとかにまとめる
自分はあまり要領や記憶力が良い方ではないので、自分の開発経験や将来何がしたいか、興味のある技術などをNotionに箇条書き程度の粒度でまとめて、オンライン面接中にも普通にチラ見していました*14。
逆求人イベントはリピートしなくていいかも
エンジニア志望だと逆求人イベントは有名かと思います。企業の人と直接話す機会なので、就活始めに参加するといいかもしれません。ただ逆求人とはいっても普通に選考は進む(一部免除)ので、企業のウェブサイトからエントリーするのとあまり変わらないなと感じました。イベントは朝から晩までで疲弊するのは必須なので、何度も参加しなくて良いと思います。
周りを気にするのをやめる
これはあんま業界関係ないですね。 一般的に就活時は基本みんな不安なので、友人などからどこを受けているだのどこか内定があるかなど聞かれることもあるかと思います。 個人的な主観ですが、基本的に他の人の選考状況は焦ったりする or 他の人にプレッシャーを与える原因になるので、私は一部の人*15以外には就活が終わるまで黙っておきました。同じ理由で掲示板みたいなのも精神衛生が悪くなるので、見るのはやめた方が良いと思います。人と比べてもしょうがないじゃないっすか。
最後に
特にずば抜けた学生じゃなくても、最低限のことをやればWeb系企業のエンジニア就活は大丈夫だよということを感じて欲しかったです。 日本の新卒一括採用は批判されることもありますが、経験がほとんど不問でエンジニアになれるのはありがたいことではないでしょうか。 何か質問があれば、@salachikeまでどうぞ。
*1:競プロ/Kaggle/有名OSS貢献/トップ国際会議でのフルペーパー論文/未踏/セキュリティキャンプなど。みなさん凄すぎます。
*2:ソフトウェアエンジニアです。
*3:最強の共著者とトップ国際会議を目指していた。1年以上かかってセカンドティア相当の国際会議にアクセプトされた。
*4:国内査読あり論文1つ、 国際会議ポスター1つ。
*5:Gitの使い方は分かりますが。
*6:研究について全く聞かれない企業もありました。長期インターン経験や有名OSSのコミッターなど、エンジニアとして即戦力になる人材が求められているのだと思いました。私は1社だけそういうところを受け、落ちました。
*7:友人の話を聞くと、外資系テック企業のエンジニア職も研究は武器にならないのかなという印象を受けました。それよりもコンピューターサイエンスの豊富な知識が求められているのでしょうか。
*8:リサーチ中心の職種だと違うかもしれません。
*9:意外と研究の話を興味を持って聞いてくれる企業が多かったのが印象的でした。
*10:https://github.com/yutaroyamanaka/marubatsu
*12:口先だけでは誰でも言えるので、研究成果やら個人開発したものなど手を動かせる人間であることを示す必要はあります。
*13:同じ企業に内定をした複数人に話を聞いたところ、全員がインターンには落ちてしまったけど本選考は受かった人でした。
*14:特にこれをしても不利益はありませんでした。
*15:先輩と後輩など就活を今してない人や特に信頼できる人。
「ゼロからのOS自作入門 」を読みました
こんにちは。salachikeです。 昨日モデルナ社のコロナワクチンを接種したのですが、かなりの筋肉痛に襲われています。(左腕が全く上がらない...)
少し前に「ゼロからのOS自作入門」を読み終えたので、読了エントリです。

購入から最後の章の実装が終わるまで、75日かかりました。 最初のころは隔日ごとに3~4時間やっていましたが、最後らへんは毎日4~5時間ぐらいやっていました。
ゼロからのOS自作入門 というTwitterのハッシュタグを見ると、1ヶ月で終えられている方もいてヒエーという感じです。
最終的な完成品を載せたツイートがこちらです。 1つの章が終わるたびに、リプライでスクショを貼っていったので興味のある人は見てみてください。
30章まで。TextViewerやImageViwerを作りました!#ゼロからのOS自作入門 pic.twitter.com/YhA2z8eM1x
— サラダチキン (@salachike) 2021年6月6日
個人的に良いと思ったことろは以下の2点です。
実装ベースでのイメージを持てる
OSの入門として、[試して理解]Linuxのしくみ という本を読んだので、システムコールやデマンドページングといった 単語について、大まかにどのようなことをするかなどの概念は知っていました。 ただこれらがどのように実現されるのかは、全くわかりませんでした。
ゼロからのOS自作入門の各章では実際にコードを書いて実装するので、 より解像度の高い理解ができると思います。
例えば CPU上で動作するタスクが切り替わるコンテキストスイッチは、 現在のタスクのレジスタ値を全てスタック上に積み、新しいタスクのレジスタの値を格納させるアセンブリコードを書くことで、 タスクの切り替えを実現します。
自分で考え、機能を拡張する機会がある
基本的にこの本はソースコードの写経がメインの作業になるのですが、 読者課題として追加機能の実装 (相対パスの実装など) が提案されています。
写経するだけでも十二分に勉強になると思いますが、読者課題に取り組むと 何となく分かっているような気になっていた点にも気づけるので、取り組むのをお勧めします。
最後に
3000円強でこれほどの内容を、日本語で学べるのは素晴らしいと思います!時間はかかりますが、やり遂げた達成感は大きいので迷っている方は是非取り組んでみてください。
今はちょっと気分を変えて、データベースシステム自作の本に取り組んでいます。 洋書ですが、頑張って読了したいと思います。
「ふつうのLinuxプログラミング」を読みました
こんにちは。salachikeです。 今年はCSの勉強を頑張っていくことを決意してから早3ヶ月...
「Linuxの仕組み」を読んだあたりからシステムコールに興味が湧き、glibcを使ってシステムコールを呼ぶようなコードを書いてOS内での挙動を理解したいと思い、ふつうのLinuxプログラミングを読むことにしました。

Twitterで「途中挫折しないか心配」ということを呟いたら、 大学の友人たちが声をかけてくれたことから、「週ごとに取り組む範囲を各自で進め、わからなかったところをDiscordで議論する」というスタイルで 読み進めていき、ちょうど2ヶ月ほどで全ての章を読み切ることができました。
この本の集大成としては、デーモンで動くHTTPサーバーを作ります。画像は動いたときの様子です!

この本で一番良いと思うところは練習問題の存在だと思います。 各種APIの紹介を眺め、その使用例を動かすだけでは「ちゃんと動いてすごいー」ぐらいの感想で終わってしまいますが、練習問題に取り組むことで自分の頭でしっかり考え。本文中の理解のあやふやだった点に気づいたということが多々ありました。
練習問題の例としては、
- fgets, fgetcなどの入出力系のAPIを説明する章では、tailコマンドの実装
- fork, exec, wait, dupなどプロセス系のAPIを説明する章では、リダイレクトやパイプが使えるshellの実装
など普通に骨のある問題が多かったですが、その分できたときの喜びは大きかったです! 自分にはただ解説があるだけの本よりも、コードを書き自分の理解と照らし合わせるような方法が合っていると思うので、 今後も手を動かす学習を継続してやっていきたいと思います。
「コンピュータシステムの理論と実装: モダンなコンピュータの作り方」を読みました
こんにちは。ほとんど外出しない生活が始まってから約1年経ちました。友達とワイワイやったり、海外に行ったりみたいなことが待ち遠しいです。
コンピューターシステムの理論と実装を読み終えたので、それの読了エントリです。

この本は別名nand2tetrisとも呼ばれており、NandゲートからOSレベルまでを一気通貫で体験しコンピューターアーキテクチャへの理解を深めるというコンセプトです。私は書籍で取り組みましたが、Courseraには著者であるヘブライ大学の教授による授業もあるようです。
各章の内容と難易度をまとめてみます。
Part1 ハードウェア
ハードウェア記述言語(HDL)でコンピューターをモデリングします。
1章 ブール論理
難易度1 ★☆☆☆☆
この本での最小の論理回路であるNandゲートを用いて、And・Or・Xor・マルチプレクサ・デマルチプレクサを実装します。多ビット・多入力の回路も後で使うので実装しますが、特に難しくはないです。
2章 ブール算術
難易度2 ★☆☆☆☆
半加算器・全加算器・加算器、そしてCPUのコアとなる部分のALU(算術論理演算器)を実装します。一見複雑ですが、仕様どおりに作れば問題ないです。
3章 順序回路
難易度2 ★★☆☆☆
最小の順序回路であるフリップフロップから、レジスタ・メモリ (RAM)・カウンタを実装します。論理回路では値を計算するだけですが、順序回路を用いることにより「状態」を扱えるようになります。
4章 機械語
難易度2 ★★☆☆☆
今回作るコンピューターでの機械語の仕様が与えられます。その仕様に合わせたアセンブラを書く課題があります。
5章 コンピューターアーキテクチャ
難易度4 ★★★★☆
今まで作った回路を総動員して、メモリ (RAM, ROM), CPUを実装します。基本的には仕様に忠実に作れば問題ないですが、私はCPUの制御ビットの処理でかなり悩みました。
Part2 ソフトウェア
何らかの高水準言語を用いて、アセンブラからVM、コンパイラ、OSまでを実装します。
6章 アセンブラ
難易度2 ★★☆☆☆
アセンブリから機械語への変換をおこなうアセンブラを実装します。私はPythonで実装しましたが、基本的には文字列処理が中心なので言語は何でも良いと思います。高水準言語で作るのでそれほど実装は難しくはないですが、一番最初に機械語でアセンブラを作った人は素晴らしいですね。
Ken Gregg's answer to How did the first assemblers get built in machine code? - Quora
7章 バーチャルマシン スタック操作
難易度3 ★★★☆☆
スタックベースのバーチャルマシンを実装します。ここら辺から仕様が難しくなってきるので、なるべく固有の文字列は定数で宣言しておき、生の文字列を書くことのないようにするといいと思います。この章を取り組んでいるときに、アセンブラがスラスラ読めるようになったのを感じました。
8章 バーチャルマシン プログラム制御
難易度5 ★★★★★
前章から、関数呼び出しができるようにします。関数を呼び出した際に、呼び出し側のリターンアドレスや各セグメントのベースアドレスなどをpushし、関数のリターンでそれを元に戻すのですがなかなかデバッグが難しいです。課題のユニットテストが全部通った時にはガッツポーズをしました。
9章 高水準言語
難易度1 ★☆☆☆☆
この本での独自言語であるJack言語の仕様が書かれています。特にやることはありません。
10章 コンパイラ 構文解析
難易度3 ★★★☆☆
Jack言語をVMコードに変換するためのコンパイラを作っています。この章ではJack言語の構文解析をおこないます。再帰下降構文解析というトップダウンからの再帰によるパーサーを実装するのですが意外と直感的に書けるのですんなり課題は終わると思います。
11章 コンパイラ コード生成
難易度5 ★★★★★
この本の最大の山場です。前章で作成したパーサーを用いて、コード生成部分を実装します。ずっとVMの仕様とテストの出力とを睨めっこしながら完成させましたが、丸4日ほどかかり 全てのテストケースが通った際にはガッツポーズをしました。 (2回目)ここまで終わるとJack言語から機械語までを一気通貫で生成することができるようになります。
12章 OS
難易度4 ★★★★☆
ここからはおまけです。OSというよりはJack言語によるライブラリのようなものを作ります。人によっては飛ばす人もいるようです。メモリのallocやdeallocの実装方法はとても参考になるので、ここだけでも取り組んで欲しいです。
感想
前提知識が特になくても、コンピューターのアーキテクチャを手を動かすことで理解できる良書だと思います。作るものに意味があるというよりは、作る過程で獲得できるイメージとCSの知識が結び付けられるのが一番良い点だと思います。特にCSを自分で学びたい人の一冊目にオススメです。
「Linuxのしくみ」を読みました
積ん読してあった本を2ヶ月ほどかけて消化していくことになったので, まず一冊目.
![[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識](https://m.media-amazon.com/images/I/51CPvtuv+wL._SL500_.jpg "[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識")
全体として非常に図がわかりやすく, スラスラ読み終わることができました. この本では以下のようなことを扱います.
プロセス生成 (fork (子プロセスを生成)とexecve (現在のプロセスを別のプロセスで置き換える))
コンテキストスイッチ (CPU上で動作するプロセスが切り替わる)
プロセスの状態 (実行, 実行待ち, スリープ, ゾンビ)
CPUのアイドル状態 (論理CPUが何のプロセスも実行してない状態)
OOMキラー
ページテーブル (仮想アドレスと物理アドレスの対応表)
デマンドページング (仮想アドレスにアクセスしてから, 初めて物理メモリが割り当てられる)
コピーオンライト
スワップアウト (物理メモリが枯渇した際にストレージ領域に一部を退避させる)
階層型ページテーブル・ヒュージページ
キャッシュメモリ (書き込まれたらダーティになる, 時間的・空間的局所性により多くのプログラムで効果的)
ページキャッシュ (読み出しの場合最初にカーネルのメモリにコピーして, 次にプロセスのメモリにコピー. 書き出しもカーネルのメモリを経由する)
ハイパースレッド (見かけの論理CPU数が増える)
クォータ (ファイルシステムの容量を制限)
キャラクタデバイス (端末やキーボードなど)とブロックデバイス(HDDとSSD) (Linuxはハードウェアデバイスを全てファイルで表現)
シーケンシャルアクセスとランダムアクセス
I/Oスケジューラー (マージ・ソート, 先読み)
ソースコードもついているので, 実際に手を動かしながら上記の項目について 体感ができる良書だと感じました.
Weakly-Supervised Image Segmentation
画像のピクセルごとにクラスを予測するセマンティックセグメンテーションは ピクセルごとに塗り絵のようなアノテーションをおこなった画像を教師データとして、学習をおこないます。 自動運転用のデータセットであるCityscapesなどのように大規模データセットとしてWeb上で公開されている場合は それを使えば良いのですが、ニッチな物体を対象にしてセグメンテーションをおこないたい場合は 自力でアノテーションをする必要があり、多くの人はやりたくないと思います。
そんな中, クラス分類モデルを利用して弱教師(Weakly Supervised)データを作成し セグメンテーションまでおこなうという取り組みがあります。 この手法の嬉しい点は、人間がおこなう必要のある作業は 画像中に写っている物体のラベル付けのみになり、ピクセルごとのアノテーションが不要になることにあります。
今回は, 2016年のECCVで発表された 「Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation」という論文 *1
を紹介したいと思います。
この論文では、Seeding Loss, Expansion Loss, Constrain Lossという3つのLossを設計し、クラス分類モデルを用いた弱教師データと条件付き確率場(CRF) を用いてセグメンテーションのための学習をおこなおうというモチベーションで、概念図は論文から引用したものですが以下のようになります。
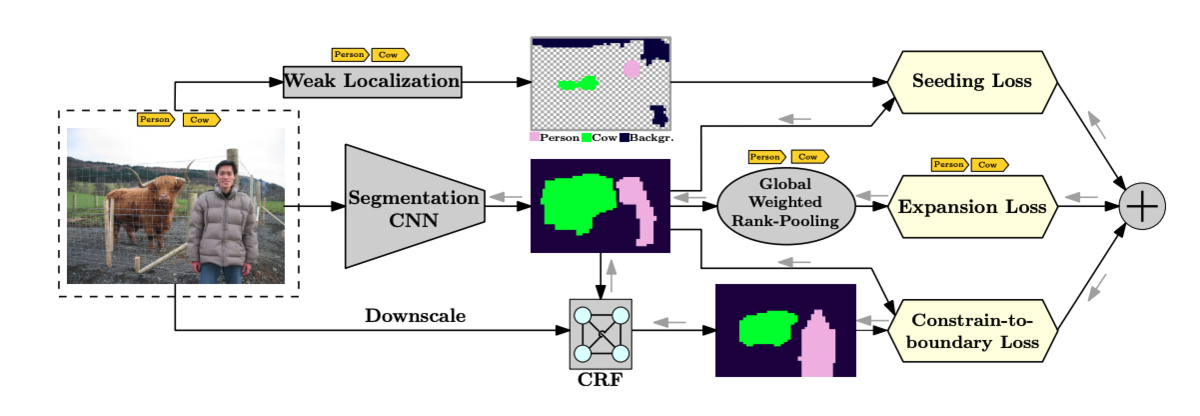
この論文では, 以下のような最適化問題を解くことで パラメータの学習をおこないます。
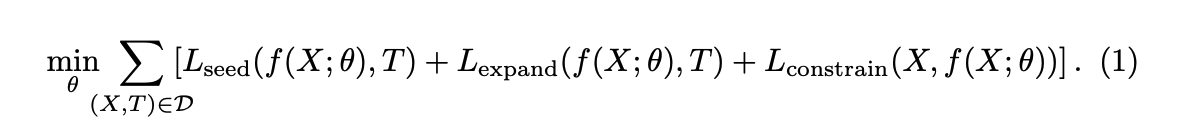
D は訓練データの集合で、 X は画像、T はクラス分類モデルによるラベル(弱教師データ)を表します。 f (X; θ) はセグメンテーションをおこなうCNNの出力です。 次はそれぞれのLossを見ていきます。
Seeding Loss
クラス分類CNNは通常, 画像中の物体の位置についての情報を得ることはできませんが、 Class Activation Map(CAM)と呼ばれる物体の位置についての手かがり(論文中ではCueと呼ばれます)を得ることができます。 CAMについては、他の記事に書いたので興味のある方は以下をご覧ください。
https://tarovel4842.hatenablog.com/entry/2019/11/24/235952tarovel4842.hatenablog.com
このCAMは弱教師データを用いるセグメンテーションでは有用な情報なのですが、 正確には物体の位置を特定することはできません。(閾値によりますが, 実際の物体の領域よりも広範囲になってしまう印象があります)
そこでこの論文ではSeeding Lossと呼ばれる, CNNにCueに適合するような出力を促すための Lossを設計をしました。
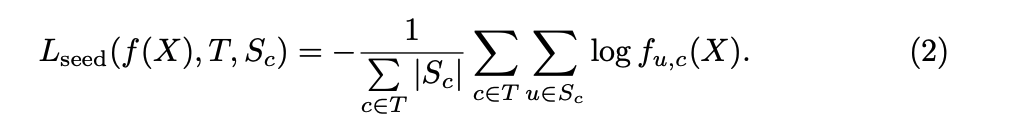
はクラスが c のCueの集合(ピクセルの集合)を表します。
Expansion Loss
CNNのあるクラスに対する出力マスクが領域として小さすぎる場合や誤った物体のラベルの出力をする場合に 罰則を課すのがExpansion Lossです。 このLossを計算するのにあたって, セグメンテーション用のCNNの出力を評価するスコアを クラス分類のスコアに落としこみ, マルチラベルの分類問題に登場するLossを適用するという方法が取られています。 スコアを計算する方法には global max-pooling (GMP) と global average-pooling (GAP)が知られています。
ピクセル数がnの画像 X, あるクラスc についてのGMPとGAPは それぞれ以下のように定義されます。
GMPは一部の箇所だけが出力値が大きくなるようにCNNに促し, 物体のサイズを過小評価する, 一方でGAPは全ての箇所で出力値が大きくなるようにCNNに促すので 物体のサイズを過大評価するという問題点が論文中で指摘されています。
そこでこの論文では, GMPとGAPを一般化したglobal weighted rank-pooling (GWRP)と呼ばれる 以下のスコアを採用しました。
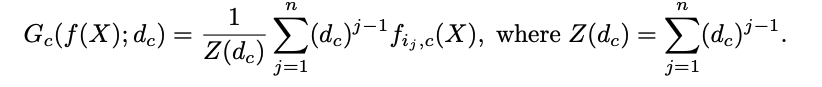
CNNの出力に現れるクラス(+), 現れないクラス(-), 背景(bg)の3つの項から構成される以下のようなLossを
Expansion Lossと定義しました。d は定数で
のように論文中の実験では定められました。
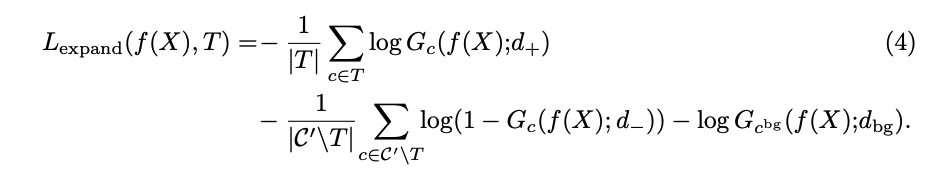
Constrain Loss
CNNが入力画像の色や空間的に対して不連続な出力をすることに罰則を設けるのがConstrain Lossです。 これによりCNNは, 物体の境界線に沿ったマスクの出力をすることができます。
CNNの出力に, fully-connected CRF (Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials*2という論文)をかけてSmoothingした出力
に対して, Constrain Lossは以下のように定義されました。
各ピクセルについて, CNNの出力とCRFの出力のKL距離の平均をとったものです。
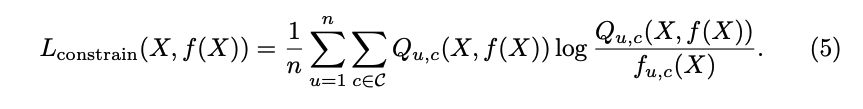
結果と感想
論文中でもベンチマークであるPASCAL VOC2012のデータセットだと以下のようなセグメンテーションの結果が得られます。 アノテーションを一切していないのに, ある程度正確なマスクを得ることができました。
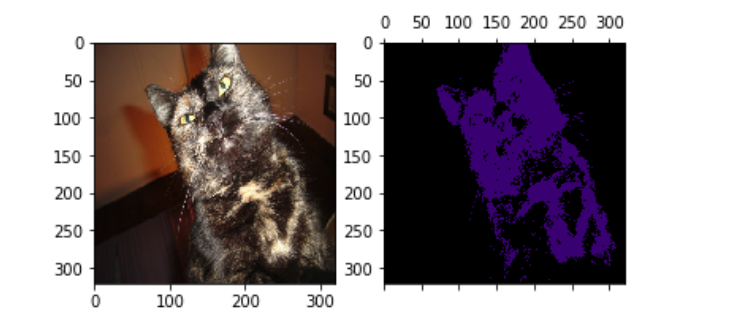
平均IoUは50%ぐらいになっていますので, やはりFull Annotatedなセグメンテーションには敵いません... 自前のデータセットで同じことをやってみたのですが, 画像中に小さく写っている物体については あまりうまくいかないようでした。
今回紹介した論文の他にも, Weakly SupervisedなSegmentation手法は多く論文があるので 他の論文も読んでみたいと思います。
Pytorchでの実装はGitHubで公開しました。 もしよろしければスターを付けていただけると、 嬉しいです。 github.com