Weakly-Supervised Image Segmentation
画像のピクセルごとにクラスを予測するセマンティックセグメンテーションは ピクセルごとに塗り絵のようなアノテーションをおこなった画像を教師データとして、学習をおこないます。 自動運転用のデータセットであるCityscapesなどのように大規模データセットとしてWeb上で公開されている場合は それを使えば良いのですが、ニッチな物体を対象にしてセグメンテーションをおこないたい場合は 自力でアノテーションをする必要があり、多くの人はやりたくないと思います。
そんな中, クラス分類モデルを利用して弱教師(Weakly Supervised)データを作成し セグメンテーションまでおこなうという取り組みがあります。 この手法の嬉しい点は、人間がおこなう必要のある作業は 画像中に写っている物体のラベル付けのみになり、ピクセルごとのアノテーションが不要になることにあります。
今回は, 2016年のECCVで発表された 「Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation」という論文 *1
を紹介したいと思います。
この論文では、Seeding Loss, Expansion Loss, Constrain Lossという3つのLossを設計し、クラス分類モデルを用いた弱教師データと条件付き確率場(CRF) を用いてセグメンテーションのための学習をおこなおうというモチベーションで、概念図は論文から引用したものですが以下のようになります。
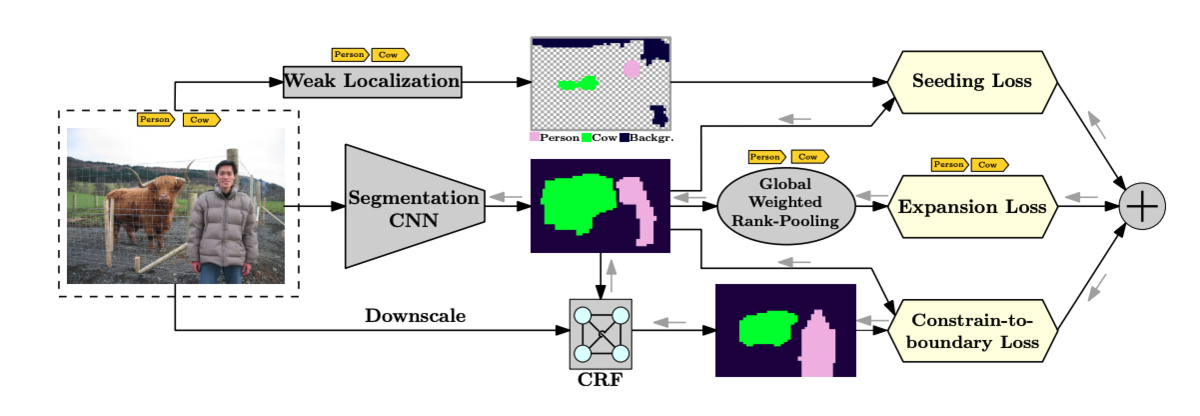
この論文では, 以下のような最適化問題を解くことで パラメータの学習をおこないます。
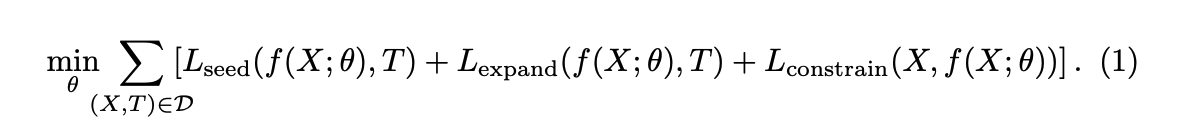
D は訓練データの集合で、 X は画像、T はクラス分類モデルによるラベル(弱教師データ)を表します。 f (X; θ) はセグメンテーションをおこなうCNNの出力です。 次はそれぞれのLossを見ていきます。
Seeding Loss
クラス分類CNNは通常, 画像中の物体の位置についての情報を得ることはできませんが、 Class Activation Map(CAM)と呼ばれる物体の位置についての手かがり(論文中ではCueと呼ばれます)を得ることができます。 CAMについては、他の記事に書いたので興味のある方は以下をご覧ください。
https://tarovel4842.hatenablog.com/entry/2019/11/24/235952tarovel4842.hatenablog.com
このCAMは弱教師データを用いるセグメンテーションでは有用な情報なのですが、 正確には物体の位置を特定することはできません。(閾値によりますが, 実際の物体の領域よりも広範囲になってしまう印象があります)
そこでこの論文ではSeeding Lossと呼ばれる, CNNにCueに適合するような出力を促すための Lossを設計をしました。
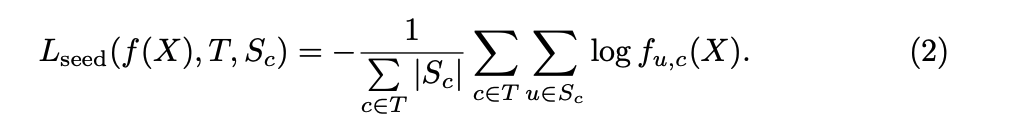
はクラスが c のCueの集合(ピクセルの集合)を表します。
Expansion Loss
CNNのあるクラスに対する出力マスクが領域として小さすぎる場合や誤った物体のラベルの出力をする場合に 罰則を課すのがExpansion Lossです。 このLossを計算するのにあたって, セグメンテーション用のCNNの出力を評価するスコアを クラス分類のスコアに落としこみ, マルチラベルの分類問題に登場するLossを適用するという方法が取られています。 スコアを計算する方法には global max-pooling (GMP) と global average-pooling (GAP)が知られています。
ピクセル数がnの画像 X, あるクラスc についてのGMPとGAPは それぞれ以下のように定義されます。
GMPは一部の箇所だけが出力値が大きくなるようにCNNに促し, 物体のサイズを過小評価する, 一方でGAPは全ての箇所で出力値が大きくなるようにCNNに促すので 物体のサイズを過大評価するという問題点が論文中で指摘されています。
そこでこの論文では, GMPとGAPを一般化したglobal weighted rank-pooling (GWRP)と呼ばれる 以下のスコアを採用しました。
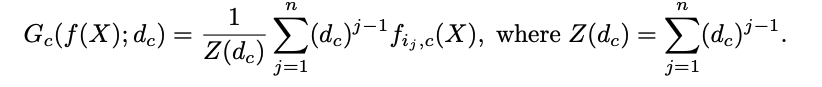
CNNの出力に現れるクラス(+), 現れないクラス(-), 背景(bg)の3つの項から構成される以下のようなLossを
Expansion Lossと定義しました。d は定数で
のように論文中の実験では定められました。
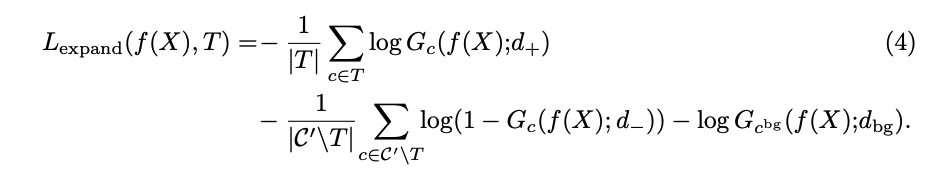
Constrain Loss
CNNが入力画像の色や空間的に対して不連続な出力をすることに罰則を設けるのがConstrain Lossです。 これによりCNNは, 物体の境界線に沿ったマスクの出力をすることができます。
CNNの出力に, fully-connected CRF (Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials*2という論文)をかけてSmoothingした出力
に対して, Constrain Lossは以下のように定義されました。
各ピクセルについて, CNNの出力とCRFの出力のKL距離の平均をとったものです。
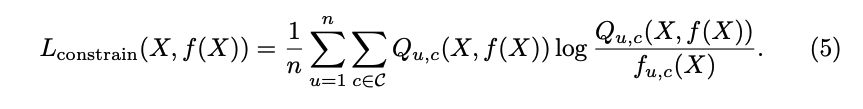
結果と感想
論文中でもベンチマークであるPASCAL VOC2012のデータセットだと以下のようなセグメンテーションの結果が得られます。 アノテーションを一切していないのに, ある程度正確なマスクを得ることができました。
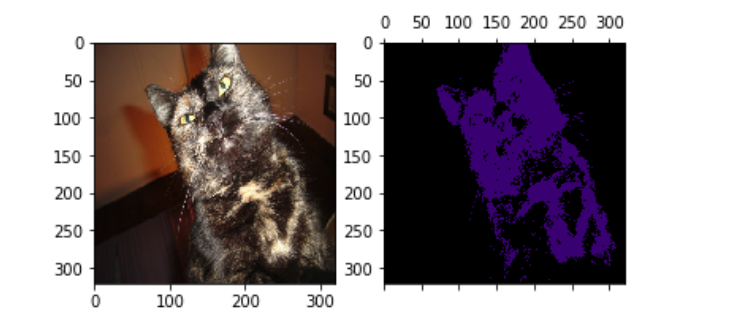
平均IoUは50%ぐらいになっていますので, やはりFull Annotatedなセグメンテーションには敵いません... 自前のデータセットで同じことをやってみたのですが, 画像中に小さく写っている物体については あまりうまくいかないようでした。
今回紹介した論文の他にも, Weakly SupervisedなSegmentation手法は多く論文があるので 他の論文も読んでみたいと思います。
Pytorchでの実装はGitHubで公開しました。 もしよろしければスターを付けていただけると、 嬉しいです。 github.com